Teoria das Categorias e Monads em Haskell
A programação funcional, especialmente na linguagem Haskell, repousa sobre fundamentos matemáticos que, embora abstratos, fornecem uma base precisa para a compreensão de como as máquinas processam informações. Entre estes fundamentos, os conceitos da Teoria das Categorias ocupam uma posição central.
Neste texto, a curiosa leitora explorará como ideias puramente matemáticas, objetos, morfismos, composição, functores, transformações naturais e monads, podem ser traduzidos em artefatos de código concretos e poderosos. Nosso objetivo é desmistificar esses termos e demonstrar como eles fornecem ferramentas interessantes para a engenharia de software. Começando, como não poderia deixar de ser, pela própria Teoria das Categorias.
Teoria das Categorias: a base conceitual
A Teoria das Categorias é um dos ramos da matemática que estuda composição. Ela não se importa com o que as coisas são, mas sim com como elas se relacionam e se compõem.
O que é uma categoria?
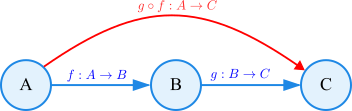
Uma categoria $\mathcal{C}$ é uma estrutura matemática, similar a um grafo direcionado, composta por:
- Objetos: $Obj(\mathcal{C})$. A cuidadosa leitora pode interpretá-los como tipos de dados (ex:
Int,String) ou conjuntos. - Morfismos: $Hom_{\mathcal{C}}(A, B)$. São as “setas” ou transformações entre objetos (ex: funções, como
show :: Int -> String). - Operação de composição: $\circ : Hom(B,C) \to Hom(A,B) \to Hom(A,C)$. Uma operação que combina morfismos de forma associativa.
- Morfismo identidade: $id_A : A \to A$. Para cada objeto $A$, existe uma seta que não faz nada.
Esta estrutura pode ser vista na figura a seguir:
Para que essa estrutura seja formalmente uma categoria, duas leis são necessárias e indispensáveis:
-
Associatividade: Para morfismos $f: A \to B$, $g: B \to C$ e $h: C \to D$: $h \circ (g \circ f) = (h \circ g) \circ f$
-
Identidade: Para qualquer morfismo $f: A \to B$:$id_B \circ f = f = f \circ id_A$
Essas leis garantem que as composições, caminhos, dentro da categoria se comportem de maneira previsível.
Exemplo concreto: a categoria Hask
Em Haskell, existe uma categoria implícita, e idealizada, chamada Hask:
| Elemento | Em Hask |
|---|---|
| Objetos | Tipos Haskell (Int, String, etc.) |
| Morfismos | Funções puras e totais |
| Composição | Operador (.) |
| Identidade | Função id |
A composição de funções em Haskell é feita com o operador (.), definido como:
(.) :: (b -> c) -> (a -> b) -> (a -> c)
E a função identidade é:id :: a -> a
As leis da categoria são, majoritariamente, garantidas pelo compilador:
-- definimos composição por .
-- Associatividade pode ser verificada assim:
h . (g . f) == (h . g) . f
-- Identidade
f . id == f -- à direita
id . f == f -- à esquerda
A figura a seguir ilustra a categoria Hask:
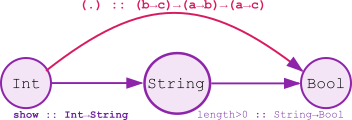
Nota sobre a pureza de Hask: a atenta leitora deve observar que, na prática, Hask não é uma categoria matemática perfeita. Isso se deve à existência de funções parciais, que falham para certas entradas e valores indefinidos (como
undefinedouerror "..."), que violam a propriedade de que morfismos devem ser totais. Contudo, ela serve como uma aproximação conceitual poderosa.
Outros Exemplos de Categorias
Embora Hask seja o nosso principal objeto de estudo, a Teoria das Categorias ganha vida por meio de exemplos e aplicações, mesmo na álgebra pura.
A Categoria Set
A categoria Set é, talvez, a categoria mais intuitiva, servindo de base para muitas outras.
| Elemento | Em Set |
|---|---|
| Objetos | Quaisquer conjuntos (ex: ${1, 2, 3}$, $\mathbb{R}$, ${\text{vermelho}, \text{azul}}$). |
| Morfismos | Funções (totais) entre conjuntos (ex: $f: \mathbb{Z} \to \mathbb{Z}$ definida por $f(x) = x^2$). |
| Composição | A composição padrão de funções, $(g \circ f)(x) = g(f(x))$. |
| Identidade | A função identidade $id_A(x) = x$ para cada conjunto $A$. |
As leis da categoria são satisfeitas:
- Associatividade: A composição de funções é inerentemente associativa, $h \circ (g \circ f) = (h \circ g) \circ f$.
- Identidade: A função $id$ atua como elemento neutro, $f \circ id_A = f$ e $id_B \circ f = f$.
A Categoria Poset
Uma categoria Poset, de Partially Ordered Set, ou Conjunto Parcialmente Ordenado, é uma construção mais sutil, em que a própria relação de ordem define os morfismos.
Seja $(P, \leq)$ um conjunto $P$ com uma relação de ordem parcial $\leq$, reflexiva, antissimétrica e transitiva. Neste caso, teremos:
| Elemento | Em Poset |
|---|---|
| Objetos | Os elementos do conjunto $P$ (ex: $1, 2, 3, \ldots$). |
| Morfismos | A própria relação. Existe um morfismo $f: A \to B$ se, e somente se, $A \leq B$. |
| Composição | A transitividade da relação. |
| Identidade | A reflexividade da relação. |
Para que esta seja uma categoria, as leis devem ser satisfeitas:
- Associatividade: se existe um morfismo $f: A \to B$ (ou seja, $A \leq B$) e $g: B \to C$ (ou seja, $B \leq C$), a composição $g \circ f$ exige um morfismo $h: A \to C$. Neste cenário, a propriedade da transitividade ($A \leq B$ e $B \leq C \implies A \leq C$) garante que este morfismo $h$ existe.
- Identidade: para todo objeto $A$, deve existir um morfismo $id_A: A \to A$. A propriedade da reflexividade ($A \leq A$) garante que este morfismo de identidade sempre existe.
Exercício 1
- Análise das Leis: Por que a lei da identidade é definida como $id_B \circ f = f = f \circ id_A$? Explique por que $id_A \circ f$ (por exemplo) não faria sentido em termos de tipos.
- Morfismos: Na categoria Hask, a função
read :: String -> Inté um morfismo válido? Justifique sua resposta considerando a definição de morfismo em Hask. (Dica: o que acontece seread "oi"for chamado?)
Functores: mapeando categorias
Se categorias são universos de objetos e morfismos, um Functor é um tradutor que mapeia um universo para outro preservando sua estrutura fundamental. Formalmente dizemos:
Um Functor $F: \mathcal{C} \to \mathcal{D}$ é um mapeamento que preserva a estrutura das categorias $\mathcal{C}$ e $\mathcal{D}$:
- Mapeia Objetos: $A \in \mathcal{C} \mapsto F(A) \in \mathcal{D}$
- Mapeia Morfismos: $(f: A \to B) \mapsto (F(f): F(A) \to F(B))$
Este mapeamento deve obedecer a duas leis:
-
Preservação da identidade:$F(id_A) = id_{F(A)}$
-
Preservação da composição:$F(g \circ f) = F(g) \circ F(f)$
Functores em Haskell
Em Haskell, quase sempre lidamos com endofunctores, functores que mapeiam Hask para Hask. A typeclass Functor captura essa ideia:
class Functor f where\
fmap :: (a -> b) -> f a -> f b
-- `f` é o mapeamento de objetos (ex: `Int` -> `Maybe Int`).
-- `fmap` é o mapeamento de morfismos (ex: `(+1)` -> uma função que aplica `(+1)` dentro do `Maybe`).
--`fmap` aplica uma função "dentro" de um contexto ou "container" (`f`).
Exemplos:
fmap (+10) (Just 5) -- Resulta em: Just 15
fmap (+1) [1,2,3] -- Resulta em: [2,3,4]
fmap length ["a","bc"] -- Resulta em: [1,2]
As leis do Functor em Haskell são a tradução direta das leis matemáticas:
-- Preservação da identidade\
fmap id == id
-- Preservação da composição\
fmap (g . f) == fmap g . fmap f
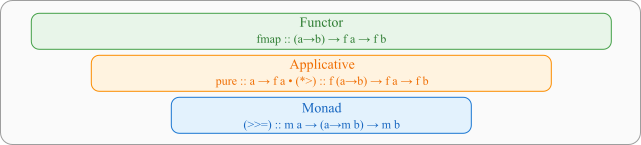
O Problema do Functor e a Solução Applicative
O fmap é excelente, mas tem uma limitação: ele só funciona quando a função, morfismo, está “do lado de fora”, pura. Neste caso, precisamos lidar com o que acontece se a própria função estiver dentro do contexto?
Just (+5) :: Maybe (Int -> Int)\
Just 10 :: Maybe Int
Não podemos usar fmap. A assinatura de fmap é (a -> b) -> f a -> f b, mas o que temos é f (a -> b).
Isso significa que fmap espera uma função pura como primeiro argumento (a -> b), enquanto no nosso caso a função está dentro do mesmo contexto f. Em outras palavras, fmap consegue aplicar uma transformação sobre um valor encapsulado, mas não consegue aplicar uma função que também está encapsulada.
A atenta leitora deve observar que o obstáculo aqui não é apenas sintático, mas estrutural: fmap opera em um único nível de contexto, e o que temos é uma aplicação entre dois valores contextualizados, uma função em f (a -> b) e um argumento em f a.
Applicative: aplicando funções em contextos
Para resolver as limitações do fmap, surge a typeclass Applicative, que estende a typeclass Functor:
class Functor f => Applicative f where
pure :: a -> f a
(<*>) :: f (a -> b) -> f a -> f b
-- `pure`: injeta um valor puro no contexto (o "menor" contexto possível).
-- `(<*>)` (lê-se "ap"): aplica uma função contextualizada a um valor contextualizado.
--Exemplo (resolvendo o problema anterior):
Just (+5) <*> Just 10 -- Resulta em: Just 15
-- E se quisermos somar dois valores em contexto?
pure (+) <*> Just 5 <*> Just 10 -- Resulta em: Just 15
-- Ele também propaga falhas (Nothing)
pure (+) <*> Just 5 <*> Nothing -- Resulta em: Nothing
A typeclass Applicative é excelente para combinar múltiplos valores independentes que estão dentro de um mesmo contexto. Ela permite aplicar funções de múltiplos argumentos sem precisar extrair explicitamente os valores do contexto, preservando a pureza e a composicionalidade do código.
O operador <*> realiza a aplicação sequencial de funções em contexto a valores também contextualizados, enquanto pure injeta uma função ou valor puro nesse contexto para iniciar a cadeia de aplicações.
Por exemplo, considere a monad Maybe, que veremos com mais cuidado a seguir e que representa computações que podem falhar:
pure (+) <*> Just 5 <*> Just 10
-- Resultado: Just 15
Neste caso, tanto a função (+) quanto os valores 5 e 10 são combinados dentro do contexto Maybe. Se algum deles for Nothing, o resultado de toda a expressão também será Nothing, mantendo a coerência do contexto:
pure (+) <*> Just 5 <*> Nothing
-- Resultado: Nothing
Da mesma forma, o comportamento se estende a listas, que representam computações com múltiplos resultados possíveis:
pure (*) <*> [1, 2] <*> [10, 100]
-- Resultado: [10, 100, 20, 200]
Aqui, o Applicative executa todas as combinações possíveis de multiplicação entre os elementos das duas listas, produzindo uma lista com todos os resultados, uma espécie de produto cartesiano funcional.
Em resumo, o Applicative generaliza o Functor: enquanto fmap aplica uma função pura a um valor em contexto, o Applicative permite aplicar funções em contexto a múltiplos valores em contexto, promovendo composição estruturada e independente dentro de ambientes computacionais.
Exercício 2
-
Em Haskell, defina as assinaturas de tipo e implemente exemplos de uso para as funções
pure,justeMaybe. -
Leis do Functor: Prove que a implementação de
fmapparaMaybeobedece às duas leis do functor.
instance Functor Maybe where
fmap _ Nothing = Nothing
fmap f (Just x) = Just (f x)
-
Leis do Functor para Listas: Prove que a implementação de
fmappara listas (map) obedece à lei da composição:fmap (g . f) == fmap g . fmap f. -
Uso de Applicative: Usando
puree(<*>), escreva uma expressão que combine trêsMaybe Stringem um únicoMaybe String(concatenando-os).
val1 = Just "a"val2 = Just "b"val3 = Just "c"- (Dica:
pure (++) <*> ...)
Computações Dependentes e o Nascimento das Monads
A Applicative é poderosa, mas ainda limitada. Ela funciona para computações independentes. Mas e se a próxima computação depender do resultado da computação anterior? Caracterizando funções em pipeline onde o resultado de uma etapa influencia a próxima.
Considere este cenário:
buscarUsuario :: String -> Maybe User
buscarPermissoes :: User -> Maybe Permissions
Não podemos usar (<*>). Precisamos do valor User de dentro do Maybe para poder passá-lo para buscarPermissoes.
É para resolver esse encadeamento dependente que surge a Monad.
Definição Categórica
Formalmente, uma Monad em uma categoria $\mathcal{C}$ é uma tripla $(T, \eta, \mu)$ que consiste em:
-
$T: \mathcal{C} \to \mathcal{C}$ — um endoFunctor (ex:
Maybe). -
$\eta: I \to T$ — uma transformação natural chamada unidade (
pure/return). Ela pega um objeto $A$ e o “injeta” no Functor, $A \to T(A)$. -
$\mu: T^2 \to T$ — uma transformação natural chamada multiplicação (
join). Ela “achata” um Functor aninhado, $T(T(A)) \to T(A)$.
A estrutura deve obedecer a certas leis, diagramas comutativos, que garantem associatividade e identidade.
A Monad na Prática: Haskell
A definição matemática é elegante, mas a definição em Haskell é, para muitos, mais prática.
A definição moderna (pós-GHC 7.10) da typeclass Monad é:
class Applicative m => Monad m where
(>>=) :: m a -> (a -> m b) -> m b
-- return = pure (não é mais parte da classe)
A atenta leitora deve prestar a atenção à dois pontos importantes:
- Toda
Monadé tambémApplicativee, portanto,Functor. - A definição mínima é apenas o operador
(>>=)(lê-se bind). A funçãoreturnagora é apenas um sinônimo parapure.
O operador (>>=) é a essência do encadeamento dependente:
(>>=) :: m a -> (a -> m b) -> m b
Ele pega (1) um valor no contexto m a, e (2) uma função (a -> m b) que sabe o que fazer com o valor a puro. O bind cuida de extrair a de m a e passá-lo para a função.
Exemplos:
-- Sucesso:\
Just 5 >>= (\x -> Just (x + 1)) -- Resulta em: Just 6
-- Falha (o 'bind' faz o short-circuit):\
Nothing >>= (\x -> Just (x + 1)) -- Resulta em: Nothing (a função nem é executada)
Relação entre join e bind
As duas definições de Monad, matemática com $\mu$ e Haskell com (>>=) são equivalentes. Podemos definir uma em termos da outra:
- bind em termos de
join + fmapSe tivéssemosjoin :: m (m a) -> m a, poderíamos definir bind:m >>= f = join (fmap f m).
Análise dos tipos a cuidadosa leitora deve verificar:
m :: m a
f :: a -> m b
fmap f m :: m (m b) (Contexto aninhado!)
join (...) :: m b (Achatado!)
- join em termos de bind
Em Haskell, podemos definir
joinfacilmente:
join :: Monad m => m (m a) -> m a\
join mma = mma >>= id
Análise dos tipos:
mma :: m (m a)
id :: m a -> m a (Aqui, o a em (a -> m b) é m a)
(>>=) aplica id ao conteúdo m a interno, achatando o resultado.
A Categoria de Kleisli — composição monádica como morfismo puro
Toda Monad em uma categoria $\mathcal{C}$ define uma nova categoria, chamada Categoria de Kleisli, denotada por $\mathcal{C}_T$, onde $T$ é o endofunctor que representa a monad.
Em termos intuitivos, a categoria de Kleisli é o espaço onde as funções que retornam valores em contexto (por exemplo, a -> Maybe b ou a -> IO b) se comportam como morfismos “puros”. Isso permite raciocinar sobre computações com efeitos da mesma forma que raciocinamos sobre funções puras.
Formalmente, para uma monad $(T, \eta, \mu)$ em $\mathcal{C}$:
- Objetos: são os mesmos objetos de $\mathcal{C}$.
- Morfismos: para objetos $A$ e $B$, temos
$Hom_{\mathcal{C}T}(A, B) = Hom{\mathcal{C}}(A, T B)$
ou seja, as setas em $\mathcal{C}_T$ são funções do tipo $A \to T B$. -
Composição: é definida usando a operação bind, ou equivalentemente $\mu$ e o funtor $T$:
\(g \circ_T f = \mu_B \circ T(g) \circ f\)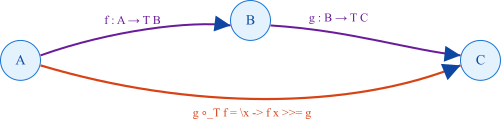
Em Haskell, essa composição é implementada pelo operador
(>=>):(>=>) :: Monad m => (a -> m b) -> (b -> m c) -> (a -> m c) f >=> g = \x -> f x >>= g - Identidade: para cada objeto $A$, a identidade é dada por
$id_A^T = \eta_A : A \to T A$,
que em Haskell corresponde areturn.
Intuição: composição de computações com efeitos
Na categoria original $\mathcal{C}$, funções puras compõem-se normalmente: \(f : A \to B,\quad g : B \to C \implies g \circ f : A \to C\)
Na categoria de Kleisli, as setas são funções que retornam valores em contexto: \(f : A \to T B,\quad g : B \to T C\)
Como não podemos compor diretamente f e g, precisamos da estrutura monádica para “encadear” essas computações:
\(g \circ_T f = \lambda x.\, f(x) >>= g\)
Assim, (>=>) é a composição categórica em $\mathcal{C}_T$.
Isso justifica matematicamente por que bind (>>=) é a operação central das Monads — ele é a composição de morfismos na categoria de Kleisli.
Exemplo em Haskell: Maybe e IO como categorias de Kleisli
- Com Maybe
f :: Int -> Maybe String
f x = if x > 0 then Just (show x) else Nothing
g :: String -> Maybe Int
g s = if length s < 3 then Just (read s + 1) else Nothing
-- Composição monádica (Kleisli)
h :: Int -> Maybe Int
h = f >=> g
Aqui, h é a composição de f e g dentro da categoria de Kleisli de Maybe.
O operador (>=>) garante que o Nothing propague corretamente e que o resultado só exista se todas as etapas anteriores forem bem-sucedidas.
- Com IO
lerNumero :: IO Int
lerNumero = do
putStrLn "Digite um número:"
readLn
mostrarDobro :: Int -> IO ()
mostrarDobro n = putStrLn ("O dobro é: " ++ show (2 * n))
programa :: IO ()
programa = lerNumero >=> mostrarDobro $ ()
No exemplo acima, lerNumero e mostrarDobro são funções () -> IO a e a -> IO b.
Na categoria de Kleisli da monad IO, elas podem ser compostas diretamente, o que garante a sequencialidade pura dos efeitos.
A categoria de Kleisli formaliza o princípio de que Monads permitem compor funções com efeitos dentro de uma estrutura que respeita as leis da composição associativa e da identidade. Ela mostra que, mesmo quando os efeitos são inevitáveis — exceções, estado, I/O —, a composição continua sendo um processo matematicamente puro e previsível.
Em resumo:
| Conceito | Categoria $\mathcal{C}$ | Categoria de Kleisli $\mathcal{C}_T$ |
|---|---|---|
| Morfismo | $A \to B$ | $A \to T B$ |
| Identidade | $id_A$ | $\eta_A$ (return) |
| Composição | $g \circ f$ | $\mu \circ T(g) \circ f$ (>=>) |
A Kleisli é, portanto, o ambiente natural das Monads — o espaço onde funções com efeitos podem ser tratadas como morfismos puros, e onde a teoria das categorias revela sua força como modelo formal da programação funcional.
Leis das Monads (em Haskell)
Toda instância de Monad deve obedecer a três leis, análogas às leis categoriais:
| Lei | Código |
|---|---|
| Identidade à esquerda | return a >>= f == f a |
| Identidade à direita | m >>= return == m |
| Associatividade | (m >>= f) >>= g == m >>= (\x -> f x >>= g) |
Essas leis garantem que o encadeamento de computações é previsível e que return é neutro.
O açúcar sintático do-notation
Encadear (>>=) pode ficar visualmente poluído. Chamamos este problema de o *inferno do callback. A linguagem Haskell fornece a do-notation como um açúcar sintático que é traduzido diretamente para chamadas de (>>=).
Este código com do:
main_do = do
x <- Just 5
y <- Just 10
return (x + y) -- Resulta em: Just 15
É traduzido pelo compilador para este código com (>>=):
main_bind =
Just 5 >>= (\x ->
Just 10 >>= (\y ->
return (x + y)))
Exemplos de Monads Importantes
Maybe Monad — falhas controladas
Modela computações que podem falhar, propagando Nothing (short-circuit) automaticamente.
safeDiv :: Int -> Int -> Maybe Int
safeDiv _ 0 = Nothing
safeDiv x y = Just (x `div` y)
program = do
a <- safeDiv 10 2 -- a = 5
b <- safeDiv a 0 -- b = Nothing
c <- safeDiv b 1 -- Esta linha nunca executa
return (c + 1) -- O resultado final é Nothing
Either Monad — falhas com mensagem
Similar ao Maybe, mas carrega um valor Left String no caso de erro.
divide :: Double -> Double -> Either String Double
divide _ 0 = Left "Divisão por zero!"
divide x y = Right (x / y)
divide 10 2 >>= (\r -> Right (r * 2)) -- Right 10.0
divide 10 0 >>= (\r -> Right (r * 2)) -- Left "Divisão por zero!"
[] (List) Monad — não determinismo
Modela computações que podem ter múltiplos resultados (ou nenhum). O bind (>>=) executa a função para cada elemento da lista e concatena os resultados.
-- 'do' em Listas = produto cartesiano / "for aninhado"
pairs xs ys = do
x <- xs -- Para cada x em xs...
y <- ys -- ...para cada y em ys...
return (x, y) -- ...produza (x, y)
pairs [1,2] [3,4]
-- Resulta em: [(1,3),(1,4),(2,3),(2,4)]
Há, aqui, um código em Haskell para a esforçada leitora explorar os conceitos que acabamos de ver.
IO Monad — efeitos colaterais puros
A linguagem Haskell é, por definição, puramente funcional. Isso significa que uma função não pode modificar o estado global do programa, nem depender de efeitos externos. Em termos matemáticos, cada função é um morfismo entre objetos (tipos), obedecendo à propriedade fundamental da pureza: a mesma entrada sempre gera a mesma saída.
Mas então surge uma questão inevitável: como uma linguagem puramente funcional pode interagir com o mundo externo, que é essencialmente impuro?
Como ler uma entrada, escrever na tela, acessar o sistema de arquivos, ou gerar um número aleatório sem quebrar a pureza funcional?
A resposta categórica é a Monad IO.
IO como Functor, Applicative e Monad
O tipo IO a não representa o valor a, mas uma descrição pura de uma computação que, quando executada, produzirá um valor de tipo a e possivelmente causará efeitos colaterais. Dessa forma, o programa em Haskell não executa ações diretamente, ele constrói uma árvore de ações que o runtime do Haskell (GHC) executará posteriormente, fora do domínio puro da linguagem.
A IO é uma instância das três abstrações fundamentais:
instance Functor IO where
fmap f io = io >>= (return . f)
instance Applicative IO where
pure = return
mf <*> mx = do
f <- mf
x <- mx
return (f x)
instance Monad IO where
(>>=) = bindIO -- definida internamente no runtime
Essas instâncias garantem que o comportamento de IO preserve as leis fundamentais de composição da teoria das categorias, permitindo combinar ações sequencialmente sem violar a pureza.
Estrutura categórica
Em termos formais, podemos enxergar IO como um endofunctor $T : \mathcal{C} \to \mathcal{C}$, onde:
- Os objetos são tipos puros de Haskell (como
Int,String,()); - Os morfismos são funções do tipo
a -> IO b; - A unidade $\eta : A \to T(A)$ é a função
return; - A multiplicação $\mu : T(T(A)) \to T(A)$ é a operação
join, que achata camadas de ações encadeadas.
Essa estrutura obedece às leis das Monads:
- Identidade à esquerda:
return a >>= f ≡ f a - Identidade à direita:
m >>= return ≡ m - Associatividade:
(m >>= f) >>= g ≡ m >>= (\x -> f x >>= g)
Essas leis asseguram que, embora as ações tenham efeitos colaterais, a composição delas seja puramente determinística no nível semântico.
Encadeamento de ações com IO
O operador (>>=) (bind) é o responsável por encadear ações de I/O, garantindo a ordem explícita de execução. A atenta leitora pode considerar um exemplo clássico de interação com o usuário:
main :: IO ()
main = do
putStrLn "Qual é o seu nome?"
nome <- getLine
putStrLn ("Olá, " ++ nome ++ "!")
O código acima é matematicamente equivalente a:
main_alt :: IO ()
main_alt =
putStrLn "Qual é o seu nome?" >>= \_ ->
getLine >>= \nome ->
putStrLn ("Olá, " ++ nome ++ "!")
Observe que putStrLn e getLine são morfismos do tipo:
putStrLn :: String -> IO ()
getLine :: IO String
Cada linha dentro do bloco do é, na verdade, uma composição monádica. A notação do é apenas uma forma conveniente de encadear operações que retornam IO.
Separação entre descrição e execução
A pureza é preservada porque a execução das ações não ocorre dentro da função, ela está apenas descrita. O runtime do Haskell é o responsável por interpretar essa descrição, realizando os efeitos colaterais no mundo real.
Isso significa que, matematicamente, cada ação IO a é um elemento de uma categoria de Kleisli associada à Monad IO:
Essa categoria permite que componhamos funções impuras, com efeitos, de maneira pura, através do operador (>=>):
(>=>) :: (a -> IO b) -> (b -> IO c) -> (a -> IO c)
f >=> g = \x -> f x >>= g
Por exemplo:
saudacao :: String -> IO ()
saudacao nome = putStrLn ("Olá, " ++ nome ++ "!")
obterNome :: IO String
obterNome = do
putStrLn "Digite seu nome:"
getLine
programa :: IO ()
programa = obterNome >>= saudacao
-- Ou, de forma categórica:
-- programa = obterNome >=> saudacao
Combinando efeitos
O poder da IO Monad aparece ao compor várias ações que produzem e consomem dados.
Por exemplo, podemos construir um pequeno programa interativo que lê números, os processa e exibe resultados:
lerNumero :: String -> IO Int
lerNumero prompt = do
putStrLn prompt
input <- getLine
return (read input)
somaNumeros :: IO ()
somaNumeros = do
x <- lerNumero "Digite o primeiro número:"
y <- lerNumero "Digite o segundo número:"
putStrLn ("A soma é: " ++ show (x + y))
Nesse caso, cada chamada de lerNumero é um morfismo () -> IO Int, e somaNumeros é a composição monádica dessas ações.
Do ponto de vista matemático, estamos compondo morfismos dentro da categoria de Kleisli de IO:
Composição e transformação de ações
Além do encadeamento sequencial, podemos transformar o resultado de ações IO com fmap e <*>, pois IO também é um Functor e um Applicative.
dobrarEntrada :: IO ()
dobrarEntrada = do
putStrLn "Digite um número:"
n <- readLn
print (n * 2)
Pode ser reescrito usando composição funcional pura:
dobrarEntrada' :: IO ()
dobrarEntrada' = fmap (*2) readLn >>= print
Ou ainda, com aplicação dentro do contexto:
dobrarEntrada'' :: IO ()
dobrarEntrada'' = print =<< fmap (*2) readLn
Esses exemplos ilustram que a Monad IO é compatível com o restante da hierarquia Functor–Applicative–Monad, mantendo as mesmas propriedades de composição funcional.
Reflexão categórica final
Do ponto de vista categórico, IO é uma monad de efeitos, cuja interpretação semântica é dada pelo functor de Kleisli:
Através de bind e return, podemos compor ações de modo associativo, mantendo a semântica pura no nível das transformações de tipos. Assim, o Haskell preserva a pureza da função matemática, enquanto expressa programas que interagem com o mundo real.
Em outras palavras, IO não quebra a pureza de Haskell — ela a estende ao domínio dos efeitos, fornecendo uma ponte entre o cálculo funcional puro e a realidade impura da execução.
A Jornada da Abstração
A jornada que a atenta leitora percorreu: Categorias → Functores → Applicatives → Monads é a espinha dorsal da programação funcional moderna.
A Teoria das Categorias não é uma abstração gratuita; ela fornece o vocabulário e as leis que garantem composicionalidade e segurança.
| Conceito Matemático | Estrutura em Haskell | Exemplo |
|---|---|---|
| Objeto | Tipo | Int |
| Morfismo | Função pura | (+1) |
| Functor (endoFunctor) | Functor |
fmap (+1) (Just 5) |
| Unidade ($\eta$) | pure / return |
pure 5 :: Maybe Int |
| Multiplicação ($\mu$) | join |
join (Just (Just 5)) |
| Monad | Monad com (>>=) |
Just 5 >>= return . (+1) |
Finalmente podemos afirmar que Monads não são mágicas: são um padrão de design formal, baseado em matemática rigorosa, para sequenciar computações dependentes de forma pura, segura e composível.
Exercício 3
-
Monad Laws: Usando a definição da
Maybemonad, prove a “Identidade à Esquerda” (return a >>= f == f a). -
do-notation: Reescreva a seguinte expressão usando
do-notation:
safeDiv 100 2 >>= (\a -> safeDiv a 5 >>= (\b -> return (b + 1))) -
List Monad: O que a seguinte expressão do calcula?
do
n <- [1, 2, 3]
guard (odd n) -- guard :: Bool -> [()]
return (n * 10)
(Dica: guard True = [()], guard False = [])
Resposta dos Exercícios
A leitora curiosa que chegou até aqui merece ver as soluções detalhadas, com explicações passo a passo, rigor matemático e código funcional. A seguir, apresentamos as respostas completas para todos os exercícios propostos, mantendo o mesmo tom didático e formal do texto principal.
Exercício 1
1. Análise das Leis: Por que a lei da identidade é definida como $id_B \circ f = f = f \circ id_A$? Explique por que $id_A \circ f$ (por exemplo) não faria sentido em termos de tipos.
Resposta:
A lei da identidade em uma categoria é definida em duas partes:
- $id_B \circ f = f$
- $f \circ id_A = f$
Isso garante que o morfismo identidade seja neutro em relação à composição, tanto à esquerda quanto à direita.
Considere os tipos em Hask:
f :: a -> b
id_A :: a -> a
id_B :: b -> b
A composição é definida como:
(.) :: (b -> c) -> (a -> b) -> (a -> c)
Agora, analise:
-
$id_B \circ f$:
id_B . f :: (a -> b) -> (b -> b) -> (a -> b)Tipo correto:
(a -> b), igual ao tipo def. -
$f \circ id_A$:
f . id_A :: (a -> a) -> (a -> b) -> (a -> b)Tipo correto:
(a -> b), igual ao tipo def.
Mas e se tentássemos $id_A \circ f$?
id_A . f :: (a -> b) -> (a -> a) -> (a -> a) -- erro!
O operador (.) exige que o tipo de saída do segundo argumento seja igual ao tipo de entrada do primeiro. Aqui:
f :: a -> bid_A :: a -> a
A saída de f é b, mas id_A espera a → incompatibilidade de tipos.
Portanto, $id_A \circ f$ não é bem-tipado em Hask, e por isso não faz parte da lei da identidade. A lei só inclui composições válidas.
2. Morfismos: Na categoria Hask, a função read :: String -> Int é um morfismo válido? Justifique considerando a definição de morfismo em Hask.
Resposta:
Em Hask (a categoria idealizada), os morfismos são funções puras e totais — ou seja, definidas para todos os valores do tipo de entrada, sem exceções ou loops infinitos.
A função:
read :: String -> Int
não é total. Por exemplo:
read "oi" -- lança exceção: Prelude.read: no parse
read "" -- exceção
read "3.14" -- exceção
Essas entradas válidas do tipo String causam falha em tempo de execução. Portanto, read viola a propriedade de totalidade.
Conclusão: read não é um morfismo válido na categoria Hask ideal.
Na prática, usamos Maybe ou Either para torná-la total:
safeRead :: String -> Maybe Int
safeRead s = case reads s of
[(x, "")] -> Just x
_ -> Nothing
Agora sim, safeRead é um morfismo em Hask.
Exercício 2
1. Defina as assinaturas de tipo e implemente exemplos de uso para pure, Just e Maybe.
Resposta:
-- pure: injeta um valor puro em um contexto Applicative
pure :: Applicative f => a -> f a
-- Just: construtor de Maybe que representa sucesso
Just :: a -> Maybe a
-- Maybe: tipo que modela computação que pode falhar
data Maybe a = Nothing | Just a
Exemplos de uso:
pure 42 :: Maybe Int
-- Just 42
pure (+) :: Maybe (Int -> Int -> Int)
-- Just (+)
Just "Haskell" :: Maybe String
-- Just "Haskell"
pure Just <*> Just 10 :: Maybe (Maybe Int)
-- Just (Just 10)
2. Leis do Functor: Prove que a implementação de fmap para Maybe obedece às duas leis.
instance Functor Maybe where
fmap _ Nothing = Nothing
fmap f (Just x) = Just (f x)
Lei 1: Preservação da identidade
\[fmap\ id = id\]-
Caso
Nothing:fmap id Nothing = Nothing = id Nothing -
Caso
Just x:fmap id (Just x) = Just (id x) = Just x = id (Just x)
Conclusão: válida.
Lei 2: Preservação da composição
\[fmap\ (g . f) = fmap\ g . fmap\ f\]-
Caso
Nothing:fmap (g . f) Nothing = Nothing (fmap g . fmap f) Nothing = fmap g Nothing = Nothing -
Caso
Just x:fmap (g . f) (Just x) = Just ((g . f) x) = Just (g (f x)) (fmap g . fmap f) (Just x) = fmap g (Just (f x)) = Just (g (f x))
Conclusão: válida.
3. Leis do Functor para Listas: Prove a lei da composição.
fmap (g . f) == fmap g . fmap f
Em listas, fmap = map.
Prova por indução estrutural:
-
Caso base: lista vazia
[]map (g . f) [] = [] (map g . map f) [] = map g [] = [] -
Caso indutivo:
x:xsmap (g . f) (x:xs) = (g (f x)) : map (g . f) xs (map g . map f) (x:xs) = map g (f x : map f xs) = g (f x) : map g (map f xs)Pela hipótese indutiva,
map (g . f) xs = map g (map f xs)→ igual.
Conclusão: válida.
4. Uso de Applicative: Combine três Maybe String em um Maybe String (concatenando).
val1, val2, val3 :: Maybe String
val1 = Just "a"
val2 = Just "b"
val3 = Just "c"
Solução:
concatThree :: Maybe String
concatThree = pure (++) <*> (pure (++) <*> val1 <*> val2) <*> val3
-- Ou, mais legível:
concatThree = pure ((++) . (++)) <*> val1 <*> val2 <*> val3
-- Resultado: Just "abc"
Alternativa com liftA3:
import Control.Applicative (liftA3)
concatThree = liftA3 (\a b c -> a ++ b ++ c) val1 val2 val3
-- Just "abc"
Exercício 3
1. Monad Laws: Prove a “Identidade à Esquerda” para Maybe.
return a >>= f == f a
Definição de return e (>>=) para Maybe:
return x = Just x
Nothing >>= _ = Nothing
(Just x) >>= f = f x
-
Caso
return a:return a >>= f = Just a >>= f = f a
Conclusão: igual a f a.
2. do-notation: Reescreva usando do.
safeDiv 100 2 >>= (\a -> safeDiv a 5 >>= (\b -> return (b + 1)))
Resposta:
result :: Maybe Int
result = do
a <- safeDiv 100 2 -- a = Just 50
b <- safeDiv a 5 -- b = Just 10
return (b + 1) -- Just 11
3. List Monad: O que a expressão calcula?
do
n <- [1, 2, 3]
guard (odd n)
return (n * 10)
Resposta:
guard b retorna [()] se b == True, ou [] se b == False.
Passo a passo:
n <- [1,2,3]→ tentan = 1,n = 2,n = 3guard (odd n):n=1:odd 1 = True→[()]n=2:odd 2 = False→[]→ elimina este ramon=3:odd 3 = True→[()]
return (n * 10):- Para
n=1:[1 * 10] = [10] - Para
n=3:[3 * 10] = [30]
- Para
Resultado final: [10, 30]
Ou seja: os números ímpares da lista original, multiplicados por 10.