
A Nvidia e a Fábrica de IA

A rápida evolução das tecnologias de treinamento e aceleração para assistentes de inteligência artificial (IA) transformou os data centers em sistemas cujo comportamento energético lembra mais instalações industriais de alta densidade do que as salas de servidores que povoam nosso imaginário.
Espera-se que o mercado de servidores de IA salte para US 204,7 bilhões em 2025. Até 2030, prevê-se que seja de US 837 bilhões, com algumas estimativas excedendo US 1,56 trilhão. Esse número entre $34\%$ e $39\%$ não é apenas uma estatística; representa uma mudança de paradigma em como a humanidade começou a ver a inteligência como um recurso computacional. A Nvidia lidera este mercado com alguma coisa entre $80\%$ e $94\%$ de participação, e sua influência é tamanha que suas decisões moldam o futuro da infraestrutura de sistemas de Inteligência Artificial.
A Goldman Sachs Research projeta que a demanda global de energia dos data centers saltará $165\%$ até 2030, de $55 \text{ GW}$ em 2023 para $145 \text{ GW}$, com picos intermediários de $92 \text{2 GW}$ em 2027. A IA, que hoje responde por $14\%$ desse consumo, alcançará $27\%$ em 2027 e $36\%$ em 2030 — podendo devorar mais de 40% dos 96 GW críticos previstos para 2026. Nos EUA, a fatia dos data centers na demanda elétrica nacional mais que dobrará, de $4\%$ para acima de $8\%$.
Esse crescimento não é apenas estatístico: é o maior gargalo físico do ecossistema de IA. Cerca de $60\%$ da nova demanda exigirá geração adicional, demandando $\text{US } 720$ bilhões em investimentos em transmissão até 2030. A matriz energética será híbrida: $30\%$ ciclo combinado a gás, $30\%$ picos a gás, $27,5\%$ solar e $12,5\%$ eólica, um equilíbrio entre urgência e transição.
Neste mercado a Nvidia é um catalisador exotérmico, se isso existisse.
Além do Cuda, a barreira quase intransponível construída nos últimos, por assim dizer, 20 anos, a empresa se destaca pela a busca constante de performance, eficiência e escalabilidade e, principalmente pela colocação perfeita no mercado. Em uma jornada de desafios constantes em mercados que incluem jogos, criptomoedas, aprendizado de máquina e agora IA generativa. Cada passo foi dado com precisão, corrigindo erros de produtos e antecipando tendências e necessidades. Sua última proposta: a fábrica de IA.
O conceito de fábrica de IA, AI Factory proposto pela NVIDIA refere-se a uma infraestrutura de computação especializada projetada para criar valor a partir de dados, gerenciando todo o ciclo de vida de sistemas de inteligência artificial, desde a ingestão de dados até o treinamento, ajuste fino e inferência de IA em alto volume.
O conceito de marketing é que esta infraestrutura irá transformar data centers em fábricas que produzem inteligência como produto principal. Transformando a inteligência em uma espécie de commodity, medida por meio de throughput de tokens, impulsionando decisões, automação e novas soluções de IA. Permitindo a criação de produtos que nossa vâ filosofia ainda não consegue imaginar.
Componentes Principais
-
Pipelines de Dados: fundamentais para construir os modelos de linguagem atuais, os LLMs, inteligentes e escaláveis, convertendo dados brutos e não estruturados em tokens estruturados de alta qualidade, garantindo limpeza e consistência.
-
Infraestrutura de Inferência de IA: suporta respostas de baixa latência e custo eficiente em ambientes de nuvem, híbridos ou on-premise, permitindo previsões em tempo real e decisões, com processos iterativos que otimizam throughput, latência e eficiência.
Ambientes on-premise, frequentemente chamados de local ou infraestrutura própria em português como falado no Brasil, referem-se a quando uma empresa mantém seus servidores, hardware e software instalados fisicamente dentro do seu próprio prédio ou data center privado, em vez de usar servidores remotos de terceiros.
-
Gêmeos Digitais (Digital Twins): permitem o design, simulação e otimização de instalações de fábricas de IA em ambientes virtuais, usando dados 3D agregados para colaboração em tempo real, testes de cenários e validação de redundâncias.
-
Infraestrutura Full-Stack: inclui hardware de alto desempenho como GPUs, CPUs, redes, armazenamento e sistemas de resfriamento avançados; o software é modular, escalável e baseado em APIs, com designs validados para atualizações contínuas.
-
Ferramentas de Automação: reduzem esforços manuais, mantendo consistência em todo o ciclo de IA, desde ajustes de hiperparâmetros até fluxos de implantação.
A implementação desta estrutura de fábrica de IA atua como um catalisador estratégico, convertendo volumes de dados brutos em inteligência acionável capaz de orientar decisões críticas e impulsionar a geração de receita. Simultaneamente, a arquitetura otimiza o ciclo de vida completo da inteligência artificial, elevando a eficiência energética e o desempenho por Watt por meio da computação acelerada. Essa base robusta não apenas viabiliza a escalabilidade da tecnologia entre os setores público e corporativo, mas também consolida um ecossistema seguro e altamente adaptável às demandas futuras.
Hoje a bússola da oportunidade aponta para o GB200 NVL72. Um sistema em forma e tamanho de rack que integra 72 GPUs Blackwell e 36 CPUs Grace, em um único sistema de refrigeração líquida.
Usando 208 bilhões de transistores, este monstro apresenta 1.440 petaflops de desempenho com precisão FP4. Com velocidade de inferência $30\times$ mais rápida e a eficiência energética $25\times$ melhor se comparada com a geração anterior do H100 não foram apenas melhorias de desempenho, mas uma reescrita dos limites físicos. Uma besta faminta por energia, capaz de consumir até $6 \text{ MW}$ em um único rack.
Sistemas como este estão levando as empresas produtoras de hardware, lideradas pela Nvidia, a acreditar que a próxima década será definida não apenas pelo número de parâmetros em modelos de IA, mas pela capacidade de alimentar esses modelos com energia suficiente para treiná-los e operá-los eficientemente. Isto chamou minha atenção. Como engenheiro eletricista, especialista em eletrônica e em alto desempenho, fiquei intrigado com as implicações técnicas e econômicas dessa mudança.
Segundo este cenário, a vantagem competitiva se concentrará em FLOPS/Watt e resfriamento eficiente. A Nvidia alega que o Blackwell melhora a eficiência energética em 25 vezes; a SuperMicro domina resfriamento líquido. Se tudo se confirmar, o mercado se dividirá: data centers AI-Ready, com energia massiva e circuitos refrigerados, prosperarão; instalações legadas, presas ao ar-condicionado, tornar-se-ão relíquias.
Em resumo, parece que o futuro da IA não dependerá apenas da quantidade de parâmetros do modelo, ou da complexidade dos algoritmos, mas da quantidade de Watts envolvida. Quem dominar a termodinâmica da computação liderará a próxima década.
Todo cuidado é pouco quando tentamos prever o futuro. A McKinsey estima que serão necessários $\text{US } 5,2 \text{trilhões}$ em investimentos de capital (CAPEX) até 2030 para atender à demanda de computação dos modelos de IA. Por outro lado, o comitê de investimento global do Morgan Stanley alertou que o atual boom de CAPEX em IA e o mercado de ações que ele sustenta podem estar mais perto do fim estrondoso do que as pessoas de bom senso gostaria.
Entra em Cena a Fábrica de IA e a Arquitetura Kyber
Em 2025, a Nvidia propôs uma nova arquitetura de distribuição de energia para data centers de IA, denominada Kyber.
A arquitetura Kyber, no contexto da fábrica de IA proposta pela NVIDIA, refere-se à próxima geração de plataforma de servidores em rack projetada para infraestrutura de IA em grande escala. Esta arquitetura é a sucessora da arquitetura Oberon e foi projetada para maximizar a densidade de GPUs por rack, expandir o tamanho das redes e otimizar o desempenho em ambientes de computação acelerada, permitindo a construção de fábricas de IA eficientes e escaláveis em escala de gigawatts. Os objetivos não são modestos e incluem:
- Formato de Alta Densidade: adota um design em estilo blade, lâmina, diferentemente de formatos tradicionais, o que permite integrar um número maior de GPUs em um único rack. Por exemplo, ela suporta configurações como 576 **GPUs Rubin Ultra em um rack, alimentadas por uma arquitetura de $800 \text{ Vdc}$** para maior eficiência energética e desempenho por Watt.
- Integração com Infraestrutura de IA: faz parte do ecossistema MGX, Modular GPU eXtensible, da NVIDIA, que inclui designs abertos e padronizados para racks e bandejas de computação. Isso facilita a construção de data centers otimizados para cargas de trabalho de IA, como treinamento de modelos grandes e inferência em tempo real, com suporte a redes de alta velocidade e resfriamento líquido.
- Eficiência e Escalabilidade: projetada para suportar clusters de GPUs de alta densidade, desbloqueando maior desempenho por GPU e permitindo mais unidades por fábrica de IA. Ela incorpora inovações como alimentação de $800 \text{ Vdc}$, que reduz perdas de energia e melhora a sustentabilidade em instalações de grande porte.
- Aplicação em Fábricas de IA: no conceito de fábrica de IA da NVIDIA, a Kyber atua como base para transformar data centers em gigafábricas de inteligência, na qual dados são processados em escala massiva para gerar valor. Ela suporta o ciclo completo de IA, desde a preparação de dados até a inferência, em ambientes que demandam alto throughput e baixa latência, como em setores de saúde, automotivo e finanças.
Essa arquitetura foi anunciada em eventos como o OCP Global Summit 2025 e o GTC 2025, representando uma evolução para data centers mais eficientes e adaptados à era da IA generativa e agente. Ela enfatiza a integração full-stack, desde o hardware (GPUs, redes e armazenamento) até o software, alinhando-se à visão de Jensen Huang de data centers como produtores de inteligência em escala industrial.
Do ponto de vista do consumo de energia, a arquitetura proposta utiliza barramentos de $800 \text{ Vdc}$ em vez dos tradicionais, entre $48$ e $54 \text{ Vdc}$. Esta mudança não é frívola; ela reflete a necessidade de lidar com cargas cada vez maiores e os desafios associados à eficiência energética e à dissipação térmica. Esta arquitetura pode ser vista na imagem a seguir:
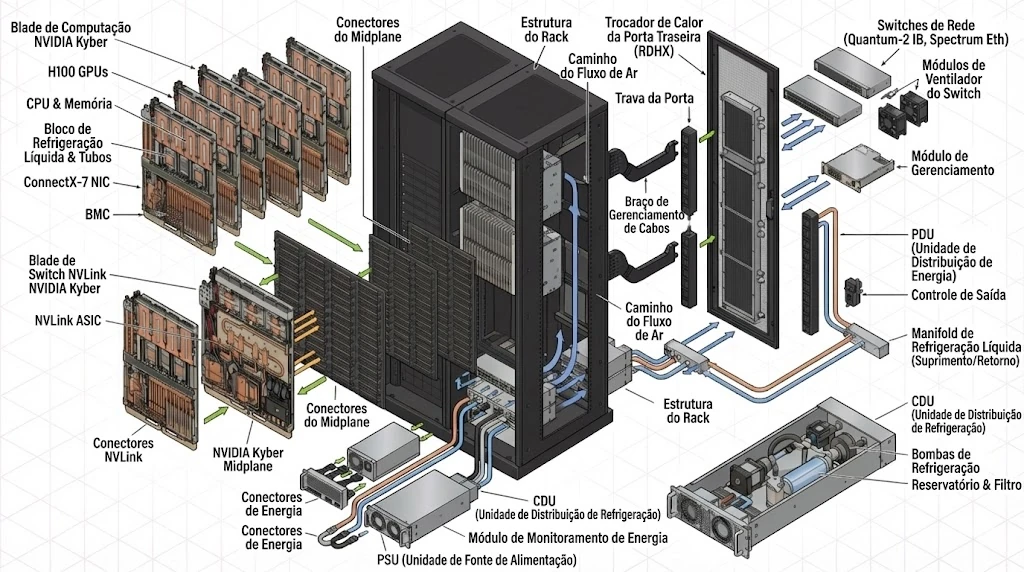 Figura 1: Diagrama simplificado da arquitetura Kyber da Nvidia, destacando a distribuição de energia em $800 \text{ Vdc}$ para racks de alta densidade de GPUs. Esta imagem foi criada pelo modelo NanoBanana em 23 de novembro de 2025 a partir das imagens publicadas por Glenn K. Lockwood e inspirada em imagem semelhante criada por @TheValueIst.
Figura 1: Diagrama simplificado da arquitetura Kyber da Nvidia, destacando a distribuição de energia em $800 \text{ Vdc}$ para racks de alta densidade de GPUs. Esta imagem foi criada pelo modelo NanoBanana em 23 de novembro de 2025 a partir das imagens publicadas por Glenn K. Lockwood e inspirada em imagem semelhante criada por @TheValueIst.
Cada detalhe desta nova arquitetura merece uma análise detalhada, talvez em outro texto. Aqui, graças a uma pulga que não sai da minha orelha, vamos analisar a proposta de mudança na arquitetura de distribuição de energia, $54 \text{ Vdc}$ para $800 \text{ Vdc}$. Esta mudança não é frívola; ela reflete a necessidade de lidar com cargas cada vez maiores e os desafios associados à eficiência energética e à dissipação térmica.
Em 2025, dominar a relação entre potência, tensão, corrente, perdas e eficiência tornou-se indispensável, sobretudo porque limites elétricos e térmicos agora restringem tanto quanto limites de interconexão ou memória. Não há energia sobrando.
Esta hipótese pode ser reforçada ao observando algumas das páginas de notícias técnicas e comunicados oficiais sobre o novo data center Kaohsiung-1 da Foxconn em Taiwan.
O Kaohsiung-1 irá operar com uma capacidade inicial de $40 \text{ MW}$ e adota a distribuição de energia em $800 \text{ Vdc}$, marcando-o como um dos primeiros projetos a utilizar essa tecnologia em escala. Localizado na cidade de Kaohsiung, o Kaohsiung-1 integra a plataforma NVIDIA GB300 NVL72, com refrigeração líquida avançada, demonstrando a viabilidade da arquitetura de alta tensão para suportar cargas de IA de alta densidade. Este data center exemplifica a transformação paradigmática impulsionada pela NVIDIA e seus parceiros como pode ser aferido nos fragmentos de informação distribuídos nos centros de imprensa e sites técnicos abaixo:
Foxconn Official Website (Hon Hai Technology Group): Um comunicado de 14 de outubro de 2025, publicado no site da Foxconn, confirma que o Kaohsiung-1 será o primeiro data center a implementar a arquitetura de energia 800 VDC em colaboração com a NVIDIA. Embora a capacidade exata de 40 MW não seja explicitamente mencionada nesse comunicado, ele destaca o projeto como um marco para AI factories.
AmpLink Tech Corp. (Global Liquid Cooling Information): Publicado em 23 de outubro de 2025, este artigo menciona explicitamente que o Kaohsiung-1 data center da Foxconn opera com 40 MW e utiliza a arquitetura 800 VDC, sendo um dos primeiros a adotar essa tecnologia para suportar a plataforma Kyber da NVIDIA.
Ingrasys (Foxconn Subsidiary): O site da Ingrasys, em 13 de outubro de 2025, reforça que o Kaohsiung-1 será um projeto de demonstração para a arquitetura 800 VDC, integrando a plataforma GB300 NVL72 com soluções de refrigeração líquida In-row CDU. A capacidade de 40 MW é mencionada em contexto com o projeto.
Reuters e Outras Fontes de Mídia: Artigos da Reuters (21 de maio de 2025) e outras publicações, como o Tribune (21 de novembro de 2025), indicam que o Kaohsiung-1 faz parte de um plano maior para um data center de 100 MW, com a fase inicial em Kaohsiung operando com 20 MW e expansões subsequentes. No entanto, o dado de 40 MW é mais precisamente corroborado pelo AmpLink Tech Corp.
NVIDIA Technical Blog e OCP Global Summit 2025: O blog da NVIDIA e relatórios do OCP Global Summit 2025 mencionam o Kaohsiung-1 como um exemplo de implementação da arquitetura 800 VDC, com foco em eficiência energética e suporte à plataforma Kyber. A capacidade de 40 MW é citada em discussões sobre a fase inicial do projeto.
Parte I: O Fluxo de Energia
O fluxo de energia de um data center moderno pode ser representado com mais rigor usando uma notação que destaca tensões, correntes, perdas e a função de cada estágio. O diagrama abaixo enfatiza a transformação e retificação desde a entrada em média tensão até o Ponto de Carga final no encapsulamento da GPU.
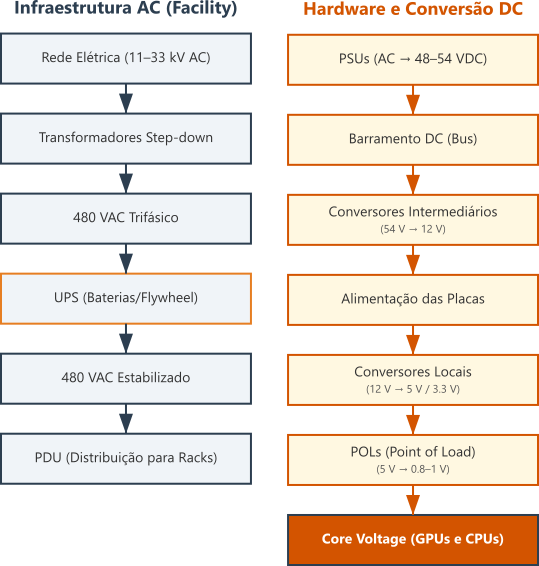 Figura 2: Diagrama simplificado do fluxo de energia em um data center tradicional usando arquitetura de $54 \text{ Vdc}$. A imagem destaca os principais estágios de conversão, perdas e tensões envolvidas desde a entrada em média tensão até o package da GPU.
Figura 2: Diagrama simplificado do fluxo de energia em um data center tradicional usando arquitetura de $54 \text{ Vdc}$. A imagem destaca os principais estágios de conversão, perdas e tensões envolvidas desde a entrada em média tensão até o package da GPU.
Um fluxo semelhante será reapresentado mais adiante para a arquitetura de $800 \text{ Vdc}$, permitindo comparação direta.
Equações Detalhadas de Cada Estágio de Conversão
Cada estágio de conversão tem uma eficiência associada. Chamaremos de $\eta_i$ a eficiência do estágio $i$. Se houver $n$ estágios, a eficiência total é:
\[\eta_{\text{total}} = \prod_{i=1}^{n} \eta_i\]PSU (480 Vac → 54 Vdc)
Supondo eficiência de $96\%$:
\[\eta_{\text{PSU}} = 0.96\]Conversão Primária (54 V → 12 V)
Eficiência típica de $97\%$:
\[\eta_{\text{prim}} = 0.97\]Conversão Secundária (12 V → 5 V)
Eficiência próxima de $95\%$:
\[\eta_{\text{sec}} = 0.95\]POL (5 V → 1 V)
Eficiência de $92\%$:
\[\eta_{\text{pol}} = 0.92\]Eficiência Total do Sistema Tradicional
Substituindo, teremos:
\[\eta_{\text{total}} = 0.96 \times 0.97 \times 0.95 \times 0.92 \eta_{\text{total}} \approx 0.81\]Isso significa que, de $120 \text{ kW}$ entregues ao rack:
\[P_{\text{útil}} = 120000 \times 0.81 = 97200\text{W}\]As perdas serão de:
\[P_{\text{perda}} = 120000 - 97200 = 22800\text{W}\]Só para enfatizar, caso a amável leitora não tenha percebido, mais de $22 \text{ kW}$ se convertem em calor antes de chegar às GPUs.
Análise Térmica Completa das Perdas e Projeções por Rack
A dissipação térmica total de um rack se decompõe em três parcelas:
- Calor gerado nos chips (GPUs e CPU);
- Calor gerado nos estágios de conversão;
- Calor gerado por perdas resistivas em cabos, conectores e barramentos.
A potência térmica é aproximadamente igual à potência perdida:
\[Q_{\text{rack}} \approx P_{\text{perda}}\]Sistema Tradicional 54 Vdc
Considerando o exemplo anterior:
\[Q_{\text{rack,54V}} \approx 22800\text{W}\]Em racks de $150 \text{ kW}$, as perdas totais sobem facilmente para $25–30 \text{ kW}$. Racks de $30 \text{ kW}$ a mais de perdas térmicas exigem sistemas de refrigeração mais robustos, que consomem mais energia elétrica, elevando o PUE (Power Usage Effectiveness).
Sistema 800 Vdc
A arquitetura Kyber reduz drasticamente o número de estágios e melhora a eficiência, levando a perdas totais inferiores a $6\%$ em cenários reais. Um diagrama de blocos desta arquitetura pode ser visto a seguir.
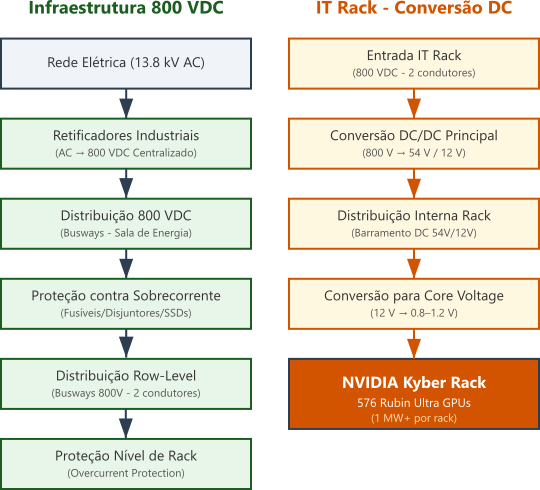 Figura 3: Diagrama simplificado do fluxo de energia em um data center usando a arquitetura Kyber de $800 \text{ Vdc}$. A imagem destaca os principais estágios de conversão, perdas e tensões envolvidas desde a entrada em média tensão até o package da GPU.
Figura 3: Diagrama simplificado do fluxo de energia em um data center usando a arquitetura Kyber de $800 \text{ Vdc}$. A imagem destaca os principais estágios de conversão, perdas e tensões envolvidas desde a entrada em média tensão até o package da GPU.
Suponha um rack de $600 \text{ kW}$:
\[\eta_{\text{kyber}} \approx 0.94\] \[P_{\text{perda}} = 600000 \times (1 - 0.94) = 36000\text{ W}\]Embora $36 \text{ kW}$ pareçam altos, o rack fornece cinco vezes mais computação que o rack de $120 \text{ kW}$ do exemplo anterior. Comparando perdas relativas:
a. Sistema $54 \text{ Vdc}$: perdas ≈ $20\%$;
b. Sistema $800 \text{ Vdc}$: perdas ≈ $6\%$.
Assim, a dissipação térmica por Watt de computação cai substancialmente.
Parte II: Comparação Completa de TCO entre 54 Vdc e 800 Vdc
O custo total de propriedade (TCO) de um data center, por simplicidade, pode ser decomposto em sete componentes principais:
- Custo do cobre e conectores;
- Custo das Power Source Units, PSUs;
- Custo térmico: CAPEX em resfriamento, OPEX em energia;
- Perdas elétricas, energia não convertida em computação;
- Manutenção;
- Espaço físico estrutural;
- Custo de engenharia associado à complexidade.
Analisando cada item, teremos:
Impacto no TCO: Análise Aprofundada
Custo de Cobre
a. Sistema $54 \text{ Vdc}$ utiliza barras e cabos grossos, frequentemente acima de $100 \text{ mm}^2$ por fase;
b. Sistema $800 \text{ Vdc}$ reduz a largura dos condutores em até $90\%$;
O custo de cobre pode diminuir em milhares de dólares por rack por ano quando considerado o ciclo de substituição e manutenção.
Custo das PSUs
As PSUs tradicionais são caras, volumosas e apresentam taxas de falha que exigem redundância. Na arquitetura Kyber:
a. PSUs desaparecem do rack;
b. A conversão é centralizada em módulos altamente eficientes;
c. A redundância fica mais simples e barata.
Custo Térmico
O calor adicional, $Q$, gerado por perdas se relaciona ao consumo de refrigeração. Aproximando que o resfriamento consome $0.3$ a $0.5 \text{ W}$ para cada Watt de calor gerado, a diferença entre $20\%$ e $6\%$ de perdas resulta em grandes economias operacionais.
Custo das Perdas Energéticas
Em um cluster de $20 \text{ MW}$:
a. Perdas de $20\%$ equivalem a $4 \text{ MW}$;
b. Perdas de $6\%$ equivalem a $1.2 \text{ MW}$;
A diferença de $2.8 \text{ MW}$ pode representar economia de milhões de dólares por ano em energia.
Manutenção
Manter dezenas de PSUs por rack é caro e arriscado. Centralizar a conversão simplifica substituições e reduz o MTBF, o intervalo mínimo entre uma falha e outra, global.
Ocupação Física
Liberar entre $20\%$ e $30\%$ do volume de um rack significa acomodar mais GPUs por metro quadrado, aumentando a densidade computacional sem ampliar a área física.
Conclusão
Olhando esta análise, fica claro que a arquitetura Kyber não é apenas uma inovação técnica, mas uma revolução econômica. A redução de custos operacionais e de capital pode ser o diferencial que permitirá às empresas manterem-se competitivas na corrida pela supremacia em IA. Resta saber se o mercado adotará essa nova arquitetura em larga escala. Os sinais são promissores, mas o tempo dirá.